Observability(관측성)
Observability는 시스템의 문제 해결을 위해 외부 출력값(로그, 메트릭, 추적)을 분석하여 시스템 내부 상태를 이해하고 예측할 수 있는 능력이다.
모니터링과의 차이점
모니터링은 이상 징후를 감지하고 경고하는 것
관측성은 시스템의 내부 상태를 이해하고 문제의 원인을 파악할 수 있게 하는 것
1. Logs (로그)
시점별 텍스트 기록
예: “사용자 A 로그인 성공”, “DB 연결 실패”, “Query 실행 시간: 30ms”
특징
- 사람이 읽기 쉬움
- 구조화/비구조화 모두 가능
- 디버깅에 매우 유용
- 양이 많아 저장 비용이 큼
2. Metrics (메트릭)
시계열 숫자 데이터(time-series data)
예: CPU 사용률, 요청 수, 에러율, 레이턴시, 메모리 사용량
특징
- 정량적, 수학적 분석 쉬움
- 알람 설정에 최적
- 저장 공간 적음
3. Traces (추적)
단일 요청이 어떤 컴포넌트를 통해 어떻게 흐르는지를 구조화한 데이터
구성 요소
- Trace: 사용자 요청 전체
- Span: Trace 내부의 개별 작업 (DB 호출, HTTP request 등)
특징
- 서비스 간 호출을 "시간순" + "트리구조"로 보여줌
- 병목 구간을 정확히 찾을 수 있음
- 마이크로초 단위까지 디테일함
정리
| 항목 | Logs | Metrics | Traces |
| 형태 | 텍스트 | 숫자 | 구조화된 트리 |
| 목적 | 디버깅 | 모니터링 & 알람 | 성능 분석 / 요청 흐름 파악 |
| 저장 시스템 | Loki | Prometheus | Tempo |
| 데이터량 | 많음 | 적음 | 중간 |
| 장점 | 상세 정보 | 빠른 집계 | 병목 정확히 찾음 |
OpenTelemetry (OTel)
애플리케이션에서 발생하는 “관측 데이터(로그·메트릭·트레이스)”를 표준 방식으로 수집하고 전송하는 오픈소스 프레임워크
목적
- 표준화된 방식으로 관측 데이터 수집
- 다양한 언어 SDK 제공(Java, Go, Node, Python 등)
- 벤더 중립적 (Grafana, Datadog, Jaeger 등 어디든 사용 가능)
- 트레이스/로그/메트릭을 동일한 스키마로 관리

구성요소
1. SDK (Instrumentation Library)
각 언어별 instrumentation
- HTTP 서버/클라이언트 자동 트레이싱
- DB 쿼리 추적
- gRPC 호출 자동 추적
- 애플리케이션 코드에서 Span, Metric, Log 기록 가능
2. OTLP Protocol
OTel이 정의한 전송 프로토콜 (gRPC/HTTP 기반)
로그/메트릭/트레이스를 한 프로토콜로 전송 가능
3. Collector (가장 중요한 핵심)
관측 데이터를 받아서 처리하는 독립 실행형 프로세스
Collector 구성 요소
- Receiver: 데이터 수신 (OTLP, Jaeger, Zipkin 등)
- Processor: 배치 처리, 샘플링, 필터링
- Exporter: Loki/Tempo/Prometheus 등으로 내보내기
Collector는 “허브” 역할을 한다.
Grafana
여러 관측 시스템(Loki, Tempo, Prometheus 등)에 연결해 데이터를 시각화하는 대시보드 플랫폼
Grafana의 역할
로그/메트릭/트레이스 UI를 제공하는 프론트엔드
Grafana 구성 요소
- Data Sources: Loki, Tempo, Prometheus 등 연결
- Dashboards: 시각화 구성
- Explore: 로그/트레이스 인터랙티브 탐색
- Alerting: 알람 설정
Grafana는 직접 데이터를 저장하지 않기 때문에 “Data Source 추가(연결)”가 반드시 필요하다.
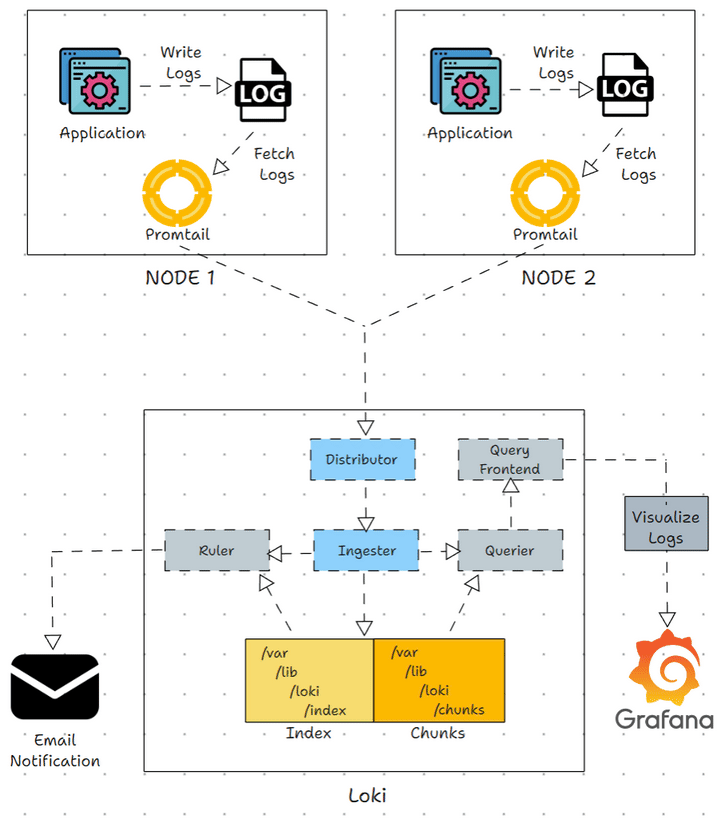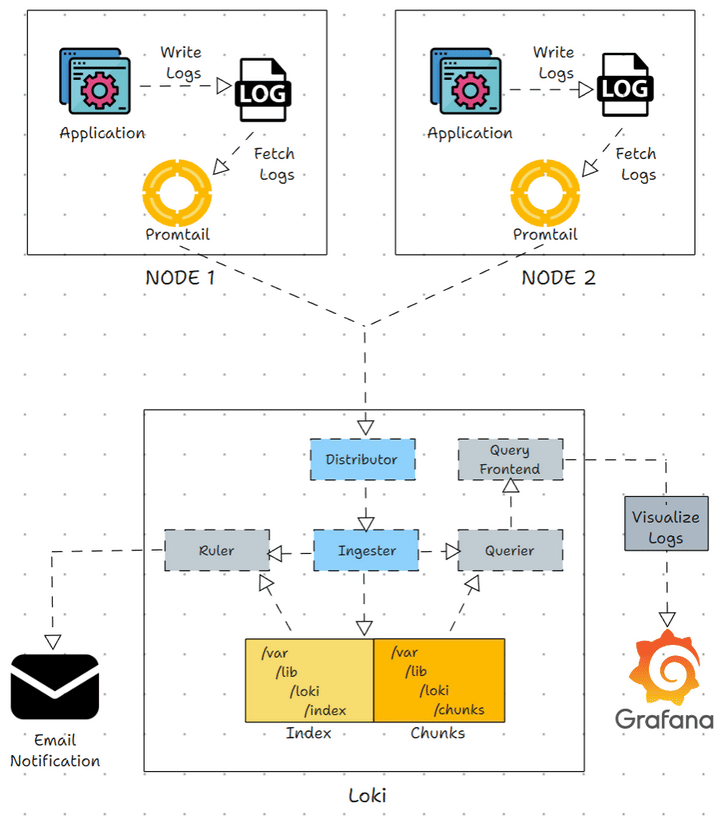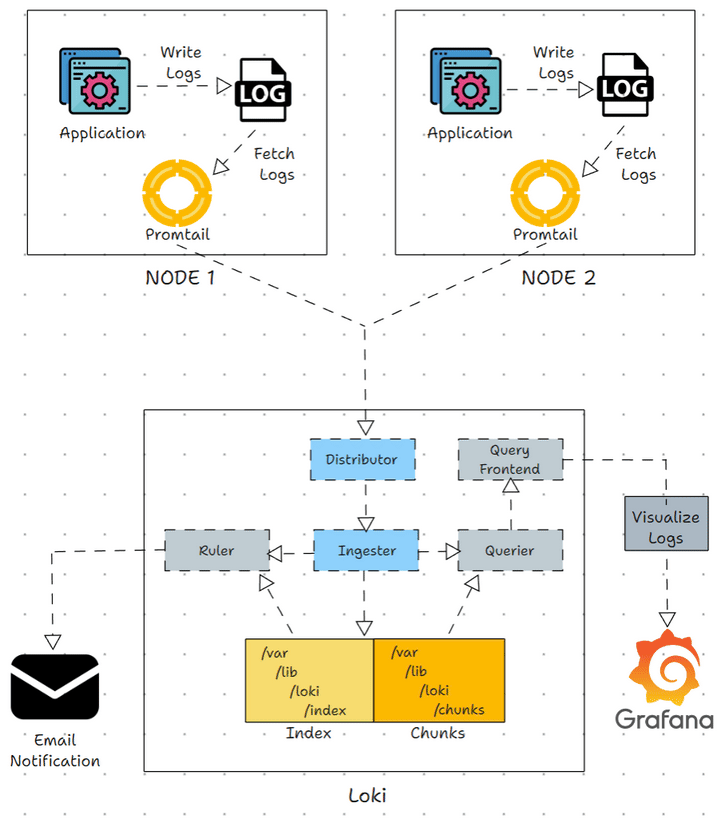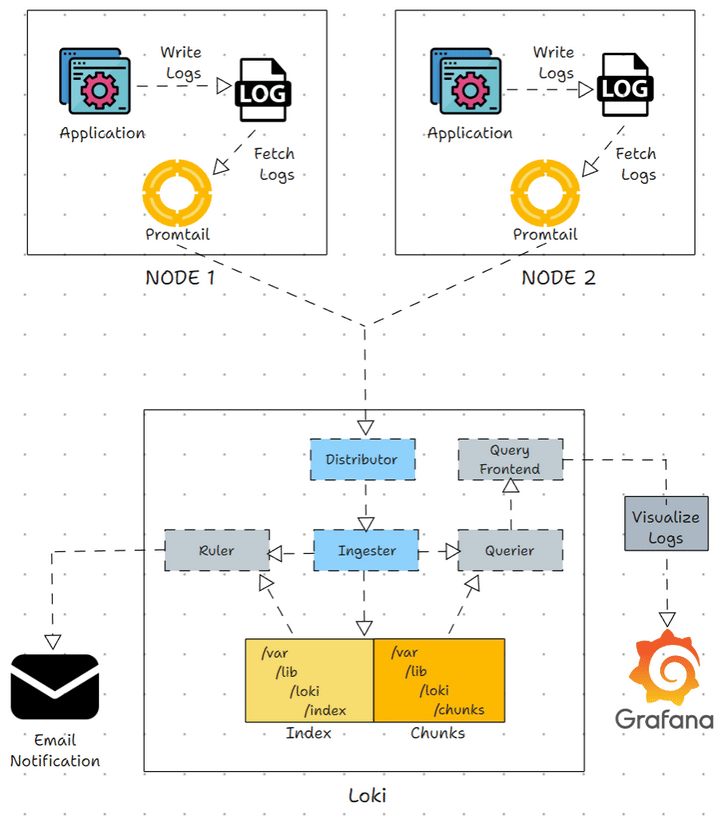
Loki
Grafana Labs에서 만든 로그 수집·저장·검색 시스템
Loki의 특징
Elasticsearch와 달리 로그 전체를 인덱싱하지 않음
대신 “라벨(metadata)”을 인덱싱하여 운영 비용 절감
실제 로그 본문은 “Chunk”로 저장
Loki 구성 요소
- Promtail 로그 수집 agent (Docker log, 파일스캐너, Kubernetes 등)
- Distributor 로그 수신
- Ingester 로그 저장
- Querier 로그 조회
- Index / Chunk Storage 실제 저장소 (S3, GCS, local filesystem 등)
Loki는 "메타데이터 중심 검색"이기 때문에
성능이 좋고 비용이 적게 든다.
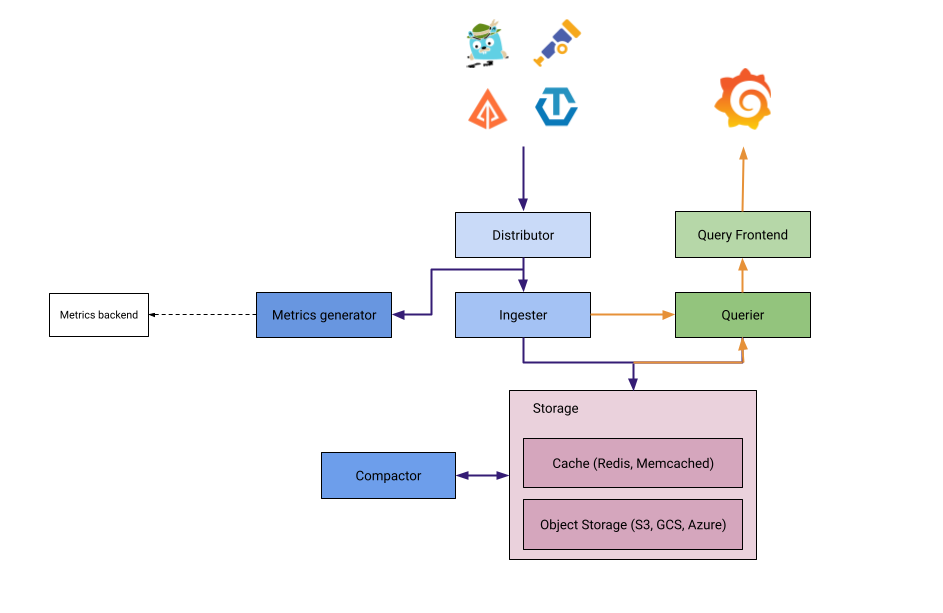
Tempo
대규모 분산 트레이싱을 저장·조회하는 시스템 (Grafana Labs 개발)
Tempo의 목표
- Jaeger/Zipkin보다 훨씬 낮은 리소스 비용
- 샘플링을 거의 안 하고도 대규모 트레이스를 저장 가능
- 인덱스 없이도 빠른 쿼리 속도
- OpenTelemetry와 완전 호환
Tempo 구성 요소
- Distributor OTLP/Jaeger/Zipkin 트레이스 수신
- Ingester 트레이스를 블록으로 변환
- Compactor 블록 정리/최적화
- Querier 트레이스 조회
- Query Frontend Query 캐싱/분배
Loki와 아키텍처가 유사함
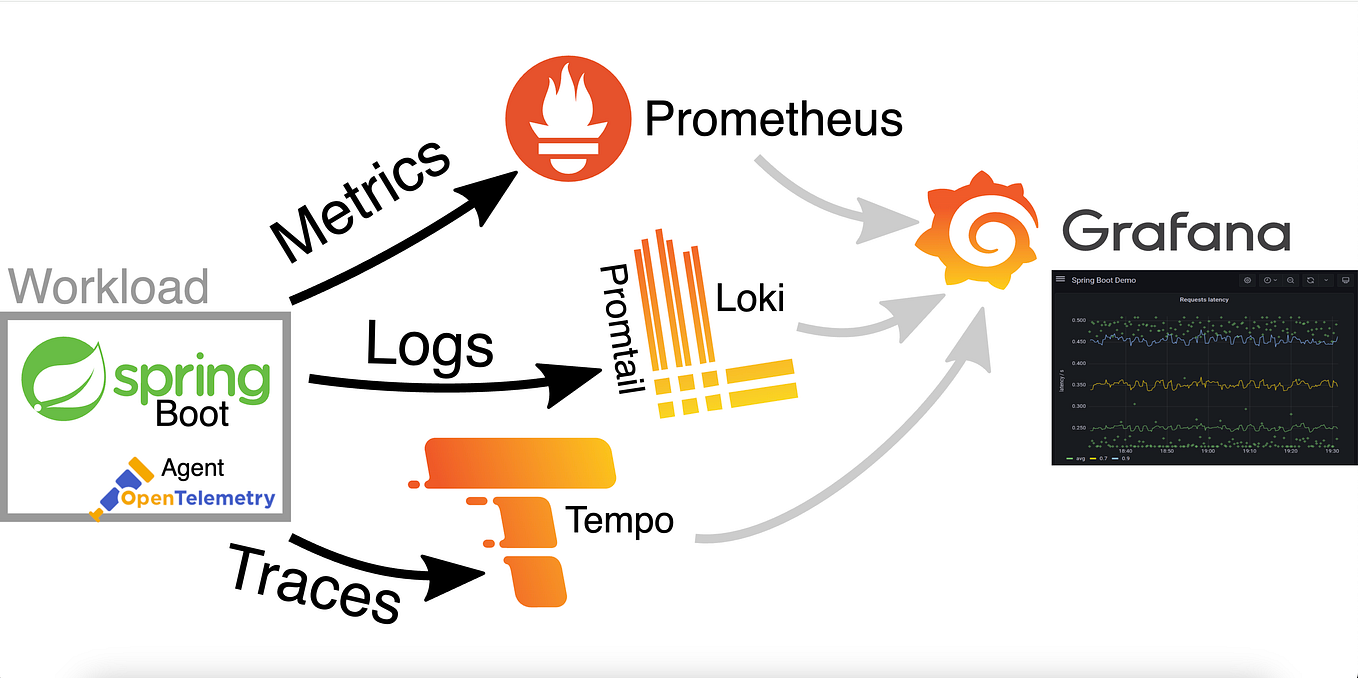
전체 구조를 하나로 엮으면?
오픈소스는 왜 하나의 통합 도구가 없을까?
상용 솔루션에서는 가능하다. (예: Datadog, NewRelic, Elastic Observability)
이유 1. Logs, Metrics, Traces의 특성이 완전히 다르기 때문
세 데이터 형식은 스토리지/검색 패턴 자체가 다르다.
Logs (텍스트, 검색중심)
- 용량 많음
- 전부 저장하면 비용 폭발
- full-text 검색을 하고 싶다면 Elasticsearch/Loki 타입의 저장소 필요
Metrics (시계열 DB)
- 초당 수십만 포인트도 흔함
- 압축·요약·롤업 필요
- TSDB(Prometheus, M3, VictoriaMetrics)가 최적화됨
Traces (트리 구조)
- 하나의 요청이 여러 Span으로 구성됨
- 인덱스 형태가 logs/metrics와 완전 다름
- Jaeger/Tempo가 최적화됨
👉 세 데이터의 형태와 질의 방식이 너무 다르기 때문에 하나의 저장소로 최적화가 사실상 불가능에 가깝다.
이유 2. 각 분야마다 “최강자” 오픈소스가 따로 있음
| 영역 | 최강자 | 이유 |
| Metrics | Prometheus | Kubernetes와 완벽 호환, Alerting 포함 |
| Logs | Loki | 비용 효율 & 라벨 기반 검색 |
| Traces | Tempo / Jaeger / Zipkin | 트레이스 저장·검색 특화 |
이렇게 각 데이터 타입에 맞는 도구들이 전문화되어 있어서 "하나로 합치기"가 오히려 비효율이기 때문.
이유 3. Observability의 등장 배경 자체가 “분산 시스템을 전문적으로 분석하려고”
단일 시스템에서는 하나의 로그만으로도 충분했지만 마이크로서비스 환경으로 오면서 구조가 아래처럼 바뀜:
API Gateway → Service A → Service B → DB → Cache …
따라서 데이터도 종류별로 분리됨
- 서비스 상태 = metrics
- 요청 흐름 = trace
- 디버깅 상세 = logs
이걸 하나의 시스템으로 운영하면 확장성 문제, 저장 비용 문제, 질의 최적화가 모두 망가진다. 그래서 Observability는 보통 이렇게 조합해서 구성한다.
[App] → (OTel SDK)
↓
[OpenTelemetry Collector]
├── Metrics → Prometheus
├── Logs → Loki
└── Traces → Tempo
[Grafana] → UI
각각의 저장소는 자기 잘하는 것만 담당하고 Grafana가 UI 레이어로 통합해서 사용성을 높임
즉, 저장의 관점에서는 도구가 분리, 시각화의 관점에서는 Grafana로 통합되는 구조.
docker compose로 구성하기
docker-compose.yml
services:
collector:
image: otel/opentelemetry-collector:0.72.0
command: ["--config=/etc/otel-collector-config.yml"]
volumes:
- ./otel-collector-config.yaml:/etc/otel-collector-config.yml
ports:
- "4317:4317"
depends_on:
- tempo
tempo:
image: grafana/tempo:latest
user: "0:0"
command: ["-config.file=/etc/tempo/config.yml"]
volumes:
- ./tempo-config.yml:/etc/tempo/config.yml
- tempo_data:/tmp/tempo
ports:
- "3200:3200" # Tempo HTTP API (Grafana가 여기 붙음)
loki:
image: grafana/loki:latest
command: ["-config.file=/etc/loki/local-config.yaml"]
volumes:
- ./loki-config.yaml:/etc/loki/local-config.yaml
- loki_data:/loki
ports:
- "3100:3100"
promtail:
image: grafana/promtail:latest
command: ["-config.file=/etc/promtail/config.yaml"]
volumes:
- ./promtail-config.yaml:/etc/promtail/config.yaml
- ./logs:/app/logs # .logs 로컬 디렉토리를 컨테이너에 마운트
depends_on:
- loki
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
depends_on:
- tempo
- loki
volumes:
- grafana_data:/var/lib/grafana
volumes:
tempo_data:
loki_data:
grafana_data:
otel-collector-config.yaml
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317 # collector가 4317 포트에서 OTLP 트레이스 수신
http: # endpoint 명시가 없어 기본 포트 사용
exporters:
otlp/tempo:
endpoint: "tempo:4317" # collector가 수신한 trace를 OTLP gRPC로 Tempo 컨테이너에 전송
tls:
insecure: true
service:
pipelines:
traces:
receivers: [otlp] # 애플리케이션이 보낸 OTLP Trace 수신
exporters: [otlp/tempo] # 수신한 trace를 Tempo로 전송👉 애플리케이션 → Collector → Tempo
tempo-config.yaml
server:
http_listen_port: 3200
distributor:
receivers:
otlp:
protocols:
grpc:
endpoint: "tempo:4317" # collector로부터 trace를 수신하는 포트
http:
endpoint: "tempo:4318"
ingester:
lifecycler:
ring:
replication_factor: 1 # For local setup, usually 1
max_block_bytes: 104857600
max_block_duration: 10m
complete_block_timeout: 15m
storage:
trace:
backend: local
wal:
path: /tmp/tempo/wal # trace를 이곳에 먼저 저장
local: # 로컬 디스크 기반 (S3 같은 object storage 대신)
path: /tmp/tempo/blocks # 일정 용량/시간이 되면 이곳에 블록 단위로 저장👉 Collector가 받은 trace를 tempo:4317 으로 OTLP로 전송
→ Tempo가 이걸 받아서 WAL + local block 파일로 저장
→ Grafana가 http://tempo:3200 으로 붙어서 trace를 조회하는 구조
promtail-config.yaml
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml # 어디까지 읽었는지 offset 저장 (이미 읽은 부분은 pass)
clients:
- url: http://loki:3100/loki/api/v1/push # 읽은 로그를 해당 url로 push
scrape_configs:
- job_name: "guardian-logs"
static_configs:
- targets:
- localhost
labels:
job: "guardian-server" # Grafana에서 쿼리할 때 사용할 필터 (job=guardian_server)
__path__: /app/logs/*.log # 마운트 된 로그 디렉토리에서 *.log 파일 모두 tail👉 애플리케이션이 ./logs/app.log, ./logs/error.log 같은 파일에 쓰면
→ docker volume으로 promtail의 /app/logs 에서 보이고
→ promtail이 tail 하다가 새 줄이 생길 때마다
→ job="guardian-server" 등의 라벨과 함께 Loki에 push
loki-config.yaml
auth_enabled: false # 로컬 환경이라 인증 없이 접근 가능
server:
http_listen_port: 3100
common:
ring:
instance_addr: 127.0.0.1
kvstore:
store: inmemory
replication_factor: 1
path_prefix: /loki
schema_config:
configs:
- from: 2020-05-15
store: tsdb # tsdb 인덱스
object_store: filesystem
schema: v13 # v13 스키마
index:
prefix: index_
period: 24h
storage_config:
filesystem:
directory: /loki/chunks # 로그 데이터 디렉토리
tsdb_shipper:
active_index_directory: /loki/index # 인덱스 정보 저장소
cache_location: /loki/index_cache
limits_config:
allow_structured_metadata: false # OTLP/structured metadata 안 쓸 거면 false
retention_period: 168h # (7일) 해당 기간 지나면 로그 삭제👉 Promtail이 보낸 로그가 job="guardian-server" 등의 라벨과 함께
→ TSDB 구조로 /loki 아래에 저장되고
→ Grafana가 http://loki:3100 으로 붙어서 쿼리할 수 있는 상태가 된다.
흐름 정리
[APP]
├─ (1) OpenTelemetry 트레이스 ─▶ collector ─▶ Tempo ─▶ Grafana (Traces)
└─ (2) Zap + lumberjack 로그(JSON) ─▶ 파일(/logs/*.log) ─▶ Promtail ─▶ Loki ─▶ Grafana (Logs)
↑
trace_id / span_id 붙어서 나감
접속해보기
Grafana (localhost:3000)

datasource 추가
loki → http://loki:3100
tempo → http://tempo:3200
